
Services






AI Solutions

"We're ready for AI," they said. Their data still lived in Google Sheets.
It usually starts with a big vision: automated workflows, predictive insights, maybe even a customer-facing AI assistant. The leadership team gives the green light, a budget is assigned, and a prototype gets built.
Then it stalls.
Not because the model is bad—but because the data underneath it is inconsistent, undocumented, and barely monitored. The most expensive part of the AI stack ends up being the part no one wants to talk about: the pipelines, the ownership, and the agreements on what things mean.
According to a 2024 RAND Corporation report, over 80% of AI projects fail - nearly double the rate of comparable IT efforts. And surprisingly, it's rarely an algorithmic issue. The common bottlenecks lie in data quality, ownership fragmentation, and unclear definitions of success
Most teams aren't skipping the hard part. They just don't know where the hard part is.
Here’s the trap: teams point to dashboards as evidence they’re data mature. Graphs exist. Metrics refresh. Business leaders feel informed.
But dashboards are a presentation. Not infrastructure. Not lineage. Not reliability.
A startup I consulted for had beautiful Looker dashboards. Real-time revenue metrics. Conversion funnels. Cohort analyses. The works. Leadership pointed to these as proof they were "AI-ready."
Dig deeper, and the rot appeared:
This wasn’t rare—it was typical. Dashboards gave the illusion of control. But beneath that veneer was entropy.
AI doesn’t need pretty charts. It needs consistent, tested, explainable data.
Everyone wants: ML-powered features, intelligent automation, predictive insights.
But few are asking: Where is the data coming from? Is it reliable? Fresh? Normalized? Labeled? Secure?
It’s not that teams are lazy. It’s that they mistake visible data for usable data. And that’s how $50k AI pilots get greenlit with a warehouse full of landmines.
IBM Watson Health tells a revealing story. Despite billions in investment, Watson struggled with oncology recommendations because it trained on "hypothetical cases" rather than messy real-world patient data. The gap between controlled environments and production reality proved fatal.
Or consider Knight Capital, which lost $440 million in 45 minutes due to a misconfigured deployment of trading algorithms—because their data and release infrastructure lacked proper safeguards. Not exactly a data quality problem in the classic sense, but a clear reminder: when data and automation collide without control, damage is rapid and irreversible.
Consider the typical e-commerce recommendation engine. The algorithm might be state-of-the-art, but if purchase history lives in one database, browsing behavior in another, and customer preferences in a third—with no reliable pipeline connecting them—the AI will make tone-deaf suggestions based on partial data.
AI is only as good as your lowest-quality data source. And most companies don't realize how low that bar really is.
Here’s the architectural reality that trips up most early-stage teams:
Your app database (OLTP) is not where AI belongs. It’s built for speed and accuracy in user-facing operations—recording transactions, logins, user settings. That’s what OLTP (Online Transaction Processing) systems like PostgreSQL, MySQL, and MongoDB excel at.
But AI—and analytics in general—requires a different kind of database: OLAP (Online Analytical Processing). These systems—BigQuery, Snowflake, Redshift—are optimized for scanning large volumes of historical data, supporting complex joins, and aggregating behavior over time.
When teams blur the line between the two, things break:
This is why modern data stacks separate concerns:
Warehousing isn't a luxury—it's a prerequisite for doing AI at all.
Every AI-mature company invests in a warehouse not because it’s fashionable, but because they’ve hit the limits of working without one.
There’s no linear roadmap to data maturity. But there are recognizable patterns. Here's a simplified model I've used with clients — not as gospel, but as a gut check:
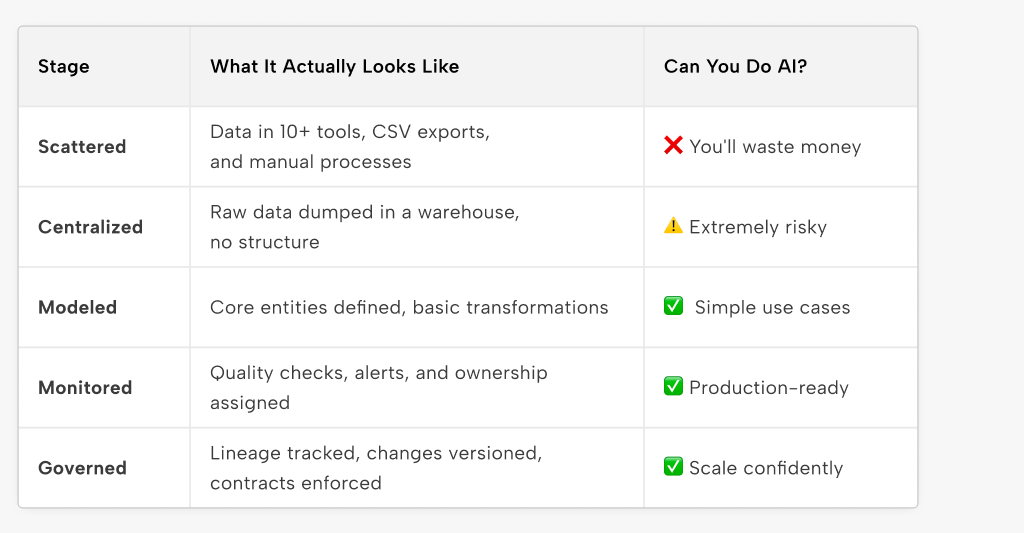
Most startups believe they're in “Modeled” territory. In reality, they're barely “Centralized.” They’ve wired up Airbyte, landed data in BigQuery, and stopped.
They build AI on raw tables with no documentation, no tests, and no versioning. Then blame the model when it misbehaves.
Let me offer a reframe:
AI readiness = (Data quality) × (Organizational discipline)
You don’t need the best tooling. You need consistent naming, reliable syncs, ownership of transformations, and testable expectations. Even a lightweight setup can support ML — if you treat it like code, not like a BI artifact.
And if you’re not there yet? That’s fine. Most companies aren’t. The danger is pretending you are.
These aren’t rare outliers. They’re predictable outcomes when AI gets bolted onto messy systems. And it’s not about bad engineers or lazy product managers. It’s about structural gaps no one accounted for.
Let’s look at how well-intentioned teams go off the rails:
The support automation that made things worse
A B2B SaaS company rolled out an AI assistant to help triage support tickets. It was trained on historical data — but that data was a mess: inconsistent tagging, free-text categories, missing resolution states. Worse, each region had different conventions. The AI learned the mess, not the resolution. Accuracy dropped. Ticket volume rose. The bot was retired.
The churn predictor nobody trusted
An e-commerce platform built a churn model to help the sales team. But key inputs — like “last active date” and “cancellation reason” — were either undefined, manually entered, or stale. The model flagged customers as likely to churn who had already renewed. The sales team stopped using it. Worse, they stopped trusting any ML output.
The forecasting tool that missed everything
A fintech startup built a revenue forecasting model. It looked good in testing — but failed hard in production. Why? Finance tracked transactions differently than product. Manual reconciliation lagged by days. And external data sources weren’t synced. The model had perfect math and flawed context. It never saw the crash coming.
AI doesn’t fail because the math is wrong. It fails because no one checked what the math was looking at.
If you want a pattern: every failure above had an invisible assumption — that "we know what the data means." Until a model proved otherwise.
The data community loves tool debates. Fivetran versus Airbyte. Snowflake versus BigQuery. dbt versus custom transformations.
Here's an observation: The best stack is the one you respect. The worst is the one you ignore.
I've seen teams succeed with basic Python scripts and PostgreSQL. I've seen others fail with cutting-edge streaming architectures. The difference? Discipline and ownership.
What actually matters:
Tools enable these practices but don't guarantee them. A sophisticated stack with poor practices fails harder than a simple stack with good habits.
Before investing in AI, ask these questions. They surface more than technical readiness—they reveal cultural habits and hidden debt:

This isn’t just engineering. It’s systems thinking. If you want AI to scale, the answer lives in your org chart as much as in your stack.
What's the real price of ignoring data fundamentals?
Engineering productivity tanks. Data scientists spending 80% of their time on data cleaning is a cliché because it's true. That $200K ML engineer becomes an expensive ETL developer.
Trust erodes slowly, then suddenly. When models and dashboards disagree, people stop believing either. Once trust is lost, rebuilding it takes months.
Technical debt compounds. Quick fixes to "just get the data" create cascading complexity. Each shortcut makes the next problem harder to solve.
And ironically: AI failures don't teach them this. They just think the model isn't good enough.
The path forward isn't about following a prescriptive timeline. It's about honest assessment and incremental progress.
Start with one critical business entity. Define it properly. Test it automatically. Assign an owner. Build trust in that data. Then expand.
This isn't exciting work. It won't generate headlines or impress investors. But it's the difference between AI that demos well and AI that delivers value.
Data pipelines aren't sufficient for AI success—but they are necessary. You also need clear objectives, realistic expectations, and organizational readiness. But without reliable data flowing through well-designed pipelines, even the best models and intentions will fail.
Here’s what it all boils down to:
AI doesn’t fail because your model was bad. It fails because your inputs were broken, your definitions were fuzzy, and your teams weren’t aligned.
This isn’t a model tuning problem. It’s an infrastructure, ownership, and communication problem.
If you want AI to be more than a prototype, you need to start in the least glamorous place: naming conventions, data tests, model ownership, and reliable ingestion.
Let’s make it brutally simple:
The companies succeeding with AI aren't necessarily smarter or better funded. They just understood that boring infrastructure work comes before exciting AI features.
They invest in:
While others chase the latest AI trends, they're building foundations that can support whatever comes next.
Before you ask "How can we use AI?"—ask "What data would we feed it?"
That one question saves you from months of churn, wasted budget, and quietly abandoned pilots.
Because most AI doesn’t fail when it’s deployed.
It fails the moment no one fixes the data.
